64 genomas humanos como nueva referencia de la diversidad genética mundial
Los nuevos datos de referencia proporcionan una base importante: El objetivo es estimar el riesgo individual de desarrollar ciertas enfermedades como el cáncer
Exactamente 20 años después de la finalización con éxito del "Proyecto Genoma Humano", un grupo internacional de investigadores, el Consorcio de Variación Estructural del Genoma Humano (HGSVC), ha secuenciado ya 64 genomas humanos en alta resolución. Estos datos de referencia incluyen individuos de todo el mundo, lo que permite captar mejor la diversidad genética de la especie humana. Entre otras aplicaciones, el trabajo permite realizar estudios específicos de la población sobre las predisposiciones genéticas a las enfermedades humanas, así como descubrir formas más complejas de variación genética, como informan los 65 autores en el número actual de la revista científica Science.
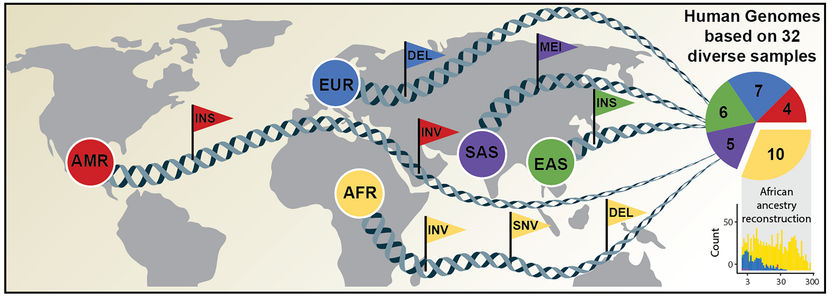
Descubrimiento exhaustivo de la variación genética basado en el análisis de genomas humanos de diversa ascendencia.
University of Washington / David Porubsky
En 2001, el "Consorcio Internacional de Secuenciación del Genoma Humano" anunció el primer borrador de la secuencia de referencia del genoma humano. El Proyecto Genoma Humano, como se denominó, había llevado más de once años de trabajo y había contado con la participación de más de 1000 científicos de 40 países. Sin embargo, esta referencia no representaba a un solo individuo, sino que es un compuesto de humanos que no podía captar con precisión la complejidad de la variación genética humana.
A partir de ahí, los científicos han llevado a cabo muchos proyectos de secuenciación en los últimos 20 años para identificar y catalogar las diferencias genéticas entre un individuo y el genoma de referencia. Esas diferencias solían centrarse en pequeños cambios de una sola base y pasaban por alto alteraciones genéticas de mayor envergadura. Ahora, las tecnologías actuales están empezando a detectar y caracterizar diferencias mayores -llamadas variantes estructurales-, como inserciones de varios cientos de letras. Las variantes estructurales tienen más probabilidades que las diferencias genéticas más pequeñas de interferir en la función de los genes.

Un equipo internacional de investigación ha publicado ahora un artículo en Science en el que anuncia un nuevo conjunto de datos de referencia considerablemente más completo, obtenido mediante una combinación de tecnologías avanzadas de secuenciación y mapeo. El nuevo conjunto de datos de referencia refleja 64 genomas humanos ensamblados, que representan 25 poblaciones humanas diferentes de todo el mundo. Es importante destacar que cada uno de los genomas se ensambló sin la guía del primer genoma humano y, como resultado, capta mejor las diferencias genéticas de las distintas poblaciones humanas. El estudio fue dirigido por científicos del Laboratorio Europeo de Biología Molecular de Heidelberg (EMBL), la Universidad Heinrich Heine de Düsseldorf (HHU), el Laboratorio Jackson de Medicina Genómica de Farmington, Conn. (JAX), y la Universidad de Washington en Seattle (UW).
"Con estos nuevos datos de referencia, las diferencias genéticas pueden estudiarse con una precisión sin precedentes en el contexto de la variación genética global, lo que facilita la evaluación biomédica de las variantes genéticas que porta un individuo", subraya el coprimer autor del estudio, el Dr. Peter Ebert, del Instituto de Biometría Médica y Bioinformática de la HHU. La distribución de las variantes genéticas puede diferir sustancialmente entre grupos de población como resultado de cambios espontáneos y continuos en el material genético. Si una mutación de este tipo se transmite a lo largo de muchas generaciones, puede convertirse en una variante genética específica de esa población.
Los nuevos datos de referencia proporcionan una base importante para incluir todo el espectro de variantes genéticas en los llamados estudios de asociación de todo el genoma. El objetivo es estimar el riesgo individual de desarrollar determinadas enfermedades, como el cáncer, y comprender los mecanismos moleculares subyacentes. Esto, a su vez, puede servir de base para terapias más específicas y medicina preventiva.
Este trabajo podría permitir otras aplicaciones en la medicina de precisión. La eficacia de los fármacos, por ejemplo, puede variar entre individuos en función de sus genomas. Los nuevos datos de referencia representan ahora toda la gama de tipos de variantes genéticas e incorporan genomas humanos de gran diversidad. Por lo tanto, este nuevo recurso podría contribuir a desarrollar nuevos enfoques en la medicina personalizada, en la que la selección de terapias se adapta a los antecedentes genéticos individuales de un paciente.
Este estudio se basa en un nuevo método publicado por estos investigadores el año pasado en Nature Biotechnology [DOI 10.1038/s41587-020-0719-5] para reconstruir con precisión los dos componentes del genoma de una persona, uno heredado del padre y otro de la madre. Al ensamblar el genoma de una persona, este método elimina los posibles sesgos que podrían resultar de las comparaciones con un genoma de referencia imperfecto.
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original
Más noticias del departamento ciencias