Proteinbibliothek für die biomedizinische Forschung
Meilenstein für die Entschlüsselung des menschlichen Proteoms
SAP und die Technische Universität München (TUM) stellen eine neue Datenbank für das menschliche Proteom vor: „ProteomicsDB“ bietet die bislang vollständigste Sammlung an Proteinen und Peptiden, die Wissenschaftler mit Hilfe der Massenspektrometrie-basierten Proteinanalytik identifiziert haben. Der derzeitige Datenbestand macht über 90 Prozent des menschlichen Proteoms aus; er bildet mehr als 18.000 Gene der etwa 20.000 menschlichen Gene ab. Mit ProteomicsDB verschaffen die beiden Partner Wissenschaftlern auf der ganzen Welt kostenfreien Zugang zu Proteindaten für die biologisch-medizinische Forschung.
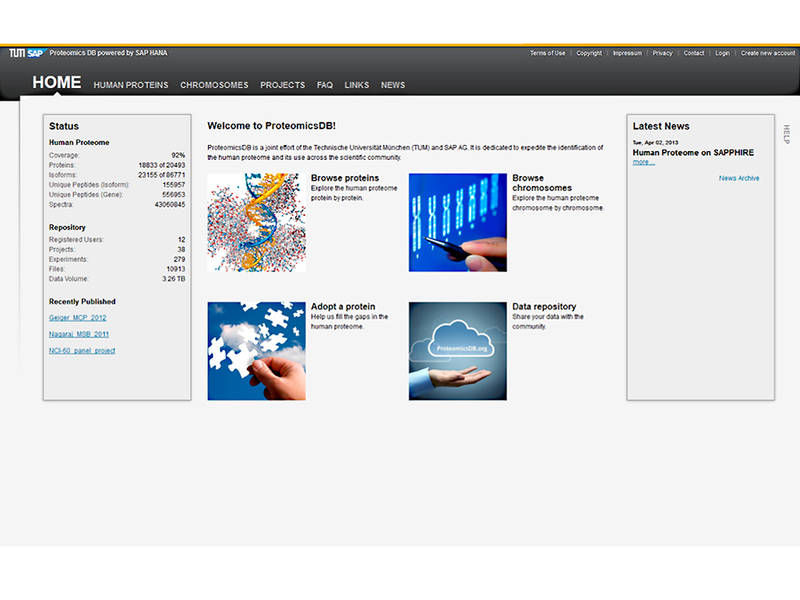
Screenshot einer Datenbank
TUM
Eines der großen Ziele der medizinischen Forschung ist es, Menschen individuell zu therapieren: Die „personalisierte“ Medizin berücksichtigt genetische Aspekte ebenso wie den Stoffwechsel und das Proteinportfolio der Patienten. Auf der Grundlage individueller Daten können Wissenschaftler neue Ansatzpunkte für Therapien, Wirkstoffkandidaten und Medikamente entwickeln. Diese Informationen lassen sich aber nur mit sehr umfangreichen Datenanalysen gewinnen.
Mit ProteomicsDB setzen SAP, das SAP Innovation Center in Potsdam und der TUM-Lehrstuhl für Proteomik und Bioanalytik einen bedeutenden Meilenstein für die Kartierung des menschlichen Proteoms. Derzeit enthält die Datenbank über 11.000 Datensätze aus menschlichen Krebszelllinien, Geweben und verschiedenen Körperflüssigkeiten.

Diese multidimensionalen Daten lassen sich unter verschiedenen Blickwinkeln darstellen, zum Beispiel in Bezug auf die chromosomale Herkunft und den Genort oder auf Übereinstimmungen mit anderen Proteinen. Auf diese Weise können wissenschaftliche Fragestellungen umgehend analysiert und bewertet werden.
Kostenfreier Zugang zum Proteom
ProteomicsDB ist eine einfach zu bedienende und schnelle Web-Anwendung, mit der sich Datensätze hochladen und durchsuchen lassen. Wie in einem Katalog können die Anwender das menschliche Proteom durchblättern und proteinspezifische Daten laden, zum Beispiel die Funktion eines Proteins oder seine Verbreitung im Gewebe.
Der Zugang zur Datenbank ist kostenfrei – und bietet Anwendern aus der Forschung sowie der Pharma- und Biotechbranche einen bisher einzigartigen Einblick in das menschliche Proteom. Mit der Auswertung von Proteindaten können Wissenschaftler künftig zum Beispiel die Entwicklung neuer Medikamente vorantreiben, die sehr gezielt in einzelne Abläufe in der Zelle eingreifen und damit Nebenwirkungen vermeiden helfen.
Robuste Plattform für komplexe Datenanalysen
Mit der Datenbank können Wissenschaftler zum einen Datensätze öffentlich zugänglich machen; zum anderen können die Nutzer über gesicherte Weblinks auch noch unveröffentlichtes Datenmaterial vorab sichten und analysieren. ProteomicsDB basiert auf der SAP HANA-Plattform und ermöglicht Rapid Data Mining und Visualisierung. Das Rückgrat der Datenbank bilden 50 Terabyte an Speicher, 2 Terabyte RAM und 160 Prozessorkerne.
Eine direkte Schnittstelle für die Programmiersprachen L, C++ und R erlaubt komplexe Rechenvorgänge, die weit über den SQL-Standard hinausgehen. Das Webinterface bedient sich eines JavaScript-Frameworks für HTML5 und ist für den Einsatz mit dem Chrome-Webbrowser optimiert, läuft aber auch unter Internet Explorer und Firefox.
Prof. Bernhard Küster beschreibt die Vorteile die Datenbank: „Mit dem Verfahren der Massenspektrometrie generiert die biomedizinische Forschung enorme Datenmengen. Für die Wissenschaftler wird es daher immer schwieriger, ‚den Wald vor all den Bäumen’ zu erkennen. ProteomicsDB ist ein bedeutender Meilenstein auf unserem Weg, Krankheiten besser zu verstehen und neue Therapiemöglichkeiten auszuloten. Die Software unterstützt Wissenschaftler und andere Zielgruppen dabei, experimentelle Daten zu speichern, zu verknüpfen und in Echt-Zeit auszuwerten. Damit können wir biologische Systeme wesentlich genauer untersuchen als bisher.“

Weitere News aus dem Ressort Wissenschaft




















Diese Produkte könnten Sie interessieren

Limsophy LIMS von AAC Infotray
Optimieren Sie Ihre Laborprozesse mit Limsophy LIMS
Nahtlose Integration und Prozessoptimierung in der Labordatenverwaltung
GUS-OS Suite von GUS
Ganzheitliche ERP-Lösung für Unternehmen der Prozessindustrie
Integrieren Sie alle Abteilungen für nahtlose Zusammenarbeit
































