Dateneffizientes Basismodell für Biomarker-Erkennung
Künstliche Intelligenz für die klinische Pathologie: Neuer Multitasking-Ansatz

In der Medizin können Systeme der Künstlichen Intelligenz (KI) Krankheiten früher erkennen, Therapien verbessern und medizinisches Personal entlasten. Wie leistungsfähig sie sind, hängt davon ab, wie gut die KI trainiert wurde. Ein neuer Multitasking-Ansatz zum Schulen von KI macht es möglich, Basismodelle mit einem Minimum an Daten kosteneffizient und schnell zu trainieren. Damit überwinden Forschende die Datenknappheit in der medizinischen Bildgebung – und können so Leben retten.
Die Zahl der Krebserkrankungen steigt laut Weltgesundheitsorganisation (WHO) weltweit signifikant an. Zentral für eine sichere Diagnose und erfolgreiche Therapie sind eindeutige Indikatoren, auch Biomarker genannt. Lernfähige KI-Systeme tragen dazu bei, solche messbaren Parameter in pathologischen Bildern aufzuspüren. Forschenden des Fraunhofer-Instituts für Digitale Medizin MEVIS ist es in Zusammenarbeit mit der RWTH Aachen, der Universität Regensburg und der Hannover Medical School gelungen, hierfür ein Basismodell zu entwickeln, das Gewebeproben anhand eines Bruchteils der üblichen Trainingsdatensätze schnell, zuverlässig und ressourceneffizient analysiert.
Weg von großen Datenmengen und selbstüberwachtem Lernen
Klassische Basismodelle, etwa Sprachmodelle wie ChatGPT, werden selbstüberwacht mit großen, diversen Datensätzen trainiert. Diese liegen jedoch bei medizinischen Bildanalysen meist nicht vor. Tatsächlich stellen die geringen Datenmengen in klinischen Studien eine große Herausforderung für die KI dar. Zudem unterscheiden sich klinische Zentren in der Aufbereitung pathologischer Präparate und der Zusammensetzung ihrer Patientenpopulation voneinander – von der spezifischen Krankheitsausprägung ganz abgesehen.
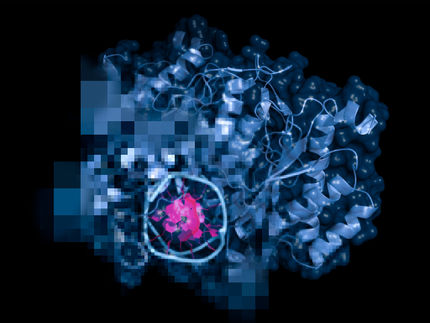
All das erschwert es, vorhandene Muster und damit diagnostisch relevante Merkmale verlässlich aufzuspüren. Um KI effektiv zu trainieren, werden daher in der Regel große Mengen an Beispielbildern unterschiedlicher Herkunft benötigt. Dabei misst jeder Gewebeschnitt typischerweise mehrere Gigabyte, enthält Tausende unterschiedlicher Zellen und spiegelt doch nur einen winzigen Bruchteil der beschriebenen Variabilität wider.
Spezialisierung nach fundierter Grundausbildung
Der Lösungsansatz des Fraunhofer MEVIS basiert auf überwachtem Vortraining. »Wir entwickeln eine Grundlagenschulung für die KI nach dem Vorbild der Ausbildung, die Pathologinnen und Pathologen durchlaufen. Sie müssen auch nicht von Fall zu Fall neu lernen, was ein Zellkern ist. Das ist Lehrbuchwissen. Einmal erfasst, sind diese Konzepte vorhanden und auf verschiedene Krankheiten übertragbar«, erklärt Fraunhofer MEVIS-Experte Dr. Johannes Lotz.
Analog dazu erlernt ihr KI-Modell in seiner Grundausbildung aus einer breiten Sammlung von Gewebeschnittbildern mit verschiedenen Fragestellungen allgemeine Merkmale und Gesetzmäßigkeiten, sogenannte Tissue Concepts. In der Kombination dieser Aufgabenstellungen entstehen die großen Datenmengen, die für das Training eines robusten KI-Basismodells benötigt werden. In einem zweiten Schritt werden die gelernten Konzepte für eine spezifische Fragestellung genutzt. Auf diese Weise können die Algorithmen mit deutlich weniger Daten Biomarker identifizieren, die etwa verschiedene Tumorarten unterscheiden.
»Bei unserer Lösung wurde jeder Datensatz von einem fachlich geschulten Menschen mit dem zu Lernenden annotiert«, erklärt Lotz‘ Teamkollege Jan Raphael Schäfer, KI-Experte am Fraunhofer MEVIS. »Wir geben unserem Modell das Bild und liefern ihm die Antwort mit. Das machen wir mit einem Multitasking-Ansatz für zahlreiche verschiedene Aufgaben gleichzeitig.«
Zudem nutzt das Team das am Institut entwickelte Bildregistrierungsverfahren HistokatFusion. Es bietet die Möglichkeit, automatisch annotierte Trainingsdaten etwa aus immunhistochemischen Gewebefärbungen zu generieren, die Proteine oder andere Strukturen mit Hilfe von markierten Antikörpern sichtbar machen. Dazu kombiniert es Informationen aus mehreren histopathologischen Bildern. Diese automatisch erzeugten Markierungen bauen die Fachleute in das Training ihres Modells ein und beschleunigen so die Sammlung von annotierten Trainingsdaten.
Beste Resultate mit nur sechs Prozent Ressourcen
Der Ansatz der Forschenden zeigt: In Vergleichstests mit klassischen, nicht-überwacht geschulten Modellen kommen die Fraunhofer-Fachleute mit lediglich sechs Prozent der Trainingsdaten aus. »Da die Anzahl der Trainingsdaten in diesem Bereich des Deep Learning mit Trainingsaufwand und Rechenleistung korreliert, werden auch nur etwa sechs Prozent der Ressourcen generell benötigt. Zudem brauchen wir gerade einmal 160 Stunden Training – ein ganz entscheidender Kostenfaktor. So können wir mit viel weniger Aufwand ein gleichwertiges Modell trainieren«, freut sich Fraunhofer MEVIS-Wissenschaftler Lotz.
Wie gut sich diese vortrainierten Modelle generalisieren lassen, zeigte die Teilnahme der Fraunhofer-Fachleute am internationalen SemiCOL Wettbewerb (Semi-supervised learning for colorectal cancer detection) zur Krebs-Klassifizierung und -Segmentierung: Hier gewann das Team bei der Klassifikation, ohne sein Modell teuer anzupassen – und belegte den zweiten Platz von insgesamt neun Teilnehmenden. Auch Tests im Bereich der interaktiven Bildsegmentierung, bei der Gewebestrukturen in einem Bild automatisch erkannt und vermessen werden, bescheinigen der Methode großes Potenzial: Das Modell benötigt nur wenige Beispiel-Bildausschnitte, um bereits erlernte Konzepte zu erweitern. Mehr noch: »Auf unserer Lösung basierende Modelle ermöglichen es, neue interaktive medizinische KI-Trainingstools zu entwickeln, bei denen Fachpersonal direkt mit KI-Lösungen interagieren und schnell entsprechende Modelle trainieren kann – ohne technisches Hintergrundwissen«, so Entwickler Schäfer.
Frei zugänglich und übertragbar
Die Forschenden veröffentlichen das vortrainierte Modell und den Code für das weiterführende Lernen auf verschiedenen Plattformen. So können Fachleute es für nicht-kommerzielle Zwecke nutzen und damit eigene Lösungen entwickeln. Das Team kooperiert darüber hinaus mit klinischen Partnern, um die Lösung in die Zulassung für die medizinische Anwendung zu überführen und sie systematisch zu validieren. Die Expertinnen und Experten am Fraunhofer MEVIS sind sich sicher: Sobald sie im Klinikalltag ankommen, verringern Systeme mit ihrem Basismodell die Arbeitsbelastung in der Pathologie und verbessern den Therapieerfolg.
Weitere News aus dem Ressort Wissenschaft





















Meistgelesene News








Weitere News von unseren anderen Portalen






















Zuletzt betrachtete Inhalte
Proteindomäne
Knockout-Maus
Die_Entstehung_der_Arten
Agitation_(Medizin)
CAR T-Therapie kann zu dauerhaften Remissionen beim Non-Hodgkin-Lymphom führen
