Ein "molekularer" Kompass zeigt den Weg zur Reduzierung von Tierversuchen
Wissenschafter*innen entwickeln intelligentes Software-Tool zur Bewertung chemischer Risiken
In den vergangenen Jahren sind Machine Learning Methoden zur Risikobewertung chemischer Verbindungen immer wichtiger geworden. Sie sind aber auch eine "Black Box" aufgrund fehlender Nachvollziehbarkeit und Transparenz, was zu Skepsis unter Fachleuten und Zulassungsbehörden führt. Um das Vertrauen in diese Modelle zu erhöhen, haben Forscher*innen der Universität Wien jene Bereiche identifiziert, in denen diese Modelle Schwächen aufweisen. Zu diesem Zweck entwickelten sie ein innovatives Software-Tool ("MolCompass").
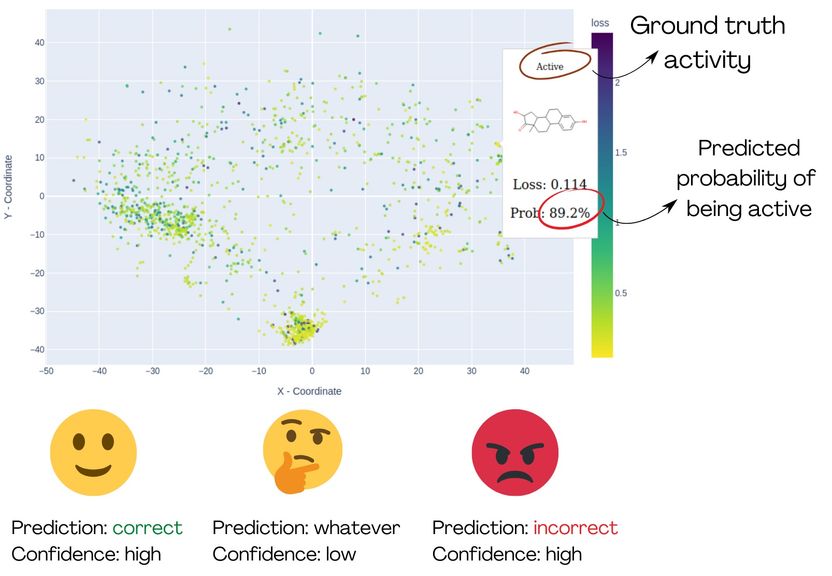
Die Demonstration von MolCompass veranschaulicht, wie Computertoxikolog*innen die betreffenden Bereiche des chemischen Raums identifizieren können. Mit Hilfe der Software können die Toxikolog*innen Regionen ausfindig machen, in denen das untersuchte Modell die Aktivität mit hoher Sicherheit falsch vorhersagt.
Sergey Sosnin
Über viele Jahrzehnte wurden neue Arzneimittel und Agrarchemikalien hauptsächlich an Tieren getestet. Diese Tests sind teuer, werfen ethische Bedenken auf und versagen oft bei der genauen Vorhersage von Nebenwirkungen am Menschen. Im Rahmen des von der Europäischen Union unterstützten Projektes RISK-HUNT3R wird – unter Mitarbeit von Wissenschafter*innen der Universität Wien – an der Entwicklung der nächsten Generation von Methoden zur tierversuchsfreien Risikobewertung neuer Substanzen geforscht. Rechnergestützte Methoden ermöglichen es mittlerweile, die toxikologischen und ökologischen Risiken neuer Chemikalien vollständig per Computer zu bewerten, ohne dass die chemischen Verbindungen synthetisiert und getestet werden müssen. Aber eine Frage bleibt: Wie vertrauenswürdig sind diese Computermodelle?
Es geht um zuverlässige Vorhersagen
Um dieses Problem näher zu untersuchen konzentrierte sich Sergey Sosnin, Senior Scientist in der Forschungsgruppe für Pharmakoinformatik an der Universität Wien, auf die binäre Klassifikation. Hierbei liefert ein maschinelles Lernmodell eine Wahrscheinlichkeit von 0 % bis 100 %, die angibt, ob eine chemische Verbindung aktiv ist oder nicht (z. B. toxisch oder nicht toxisch, bioakkumulierbar oder nicht bioakkumulierbar, ein Binder oder Nicht-Binder an ein spezifisches menschliches Protein). Diese Wahrscheinlichkeit spiegelt das Vertrauen des Modells in seine Vorhersage wider. Idealerweise sollte das Modell nur bei korrekten Vorhersagen Werte nahe 0% (sicher inaktiv) oder 100% (Sicher aktiv) geben. Wenn das Modell unsicher ist und eine Vertrauensbewertung von z.B. 51 % abgibt, sollten diese Vorhersagen verworfen und alternative Methoden zur Risikobewertung herangezogen werden. Ein Problem entsteht jedoch dann, wenn das Modell falsche Vorhersagen mit hohen Wahrscheinlichkeiten liefert.
"Dies ist das wahre Albtraumszenario für Toxikolog*innen", sagt Sergey Sosnin. "Wenn ein Modell vorhersagt, dass eine Verbindung mit 99 % Sicherheit nicht toxisch ist, die Verbindung aber tatsächlich toxisch ist, gibt es keine Möglichkeit zu wissen, dass etwas falsch gelaufen ist." Die einzige Lösung besteht darin, jene Bereiche des chemischen Raums – also mögliche Klassen organischer Verbindungen – im Voraus zu identifizieren, in denen das Modell "blinde Flecken" hat, und diese zu vermeiden. Dazu müssen Forscher*innen, die das Modell bewerten, die vorhergesagten Ergebnisse für Tausende von chemischen Verbindungen einzeln überprüfen – eine mühsame und fehleranfällige Aufgabe.
Überwindung dieses bedeutenden Hindernisses
"Um diese Forschenden zu unterstützen", fährt Sosnin fort, "entwickelten wir interaktive grafische Werkzeuge, die chemische Verbindungen auf eine 2D-Ebene projizieren, ähnlich wie geografische Karten. Mit Farben heben wir die Verbindungen hervor, die mit hoher Sicherheit falsch vorhergesagt wurden, sodass Benutzer*innen sie als Cluster roter Punkte identifizieren können. Die Karte ist interaktiv und ermöglicht es den Benutzer*innen, den chemischen Raum zu untersuchen und besorgniserregende Bereiche zu erkunden."
Die Methodik wurde anhand eines Modells zur Bindung an den Östrogenrezeptor getestet. Nach der visuellen Analyse des chemischen Raums wurde klar, dass das Modell gut für z. B. Steroide und polychlorierte Biphenyle funktioniert, aber bei kleinen, nicht zyklischen Verbindungen völlig versagt und daher nicht für diese verwendet werden sollte.
Die in diesem Projekt entwickelte Software ist der wissenschaftlichen Community frei zugänglich auf GitHub verfügbar. Sergey Sosnin hofft, dass MolCompass Chemiker*innen und Toxikolog*innen zu einem besseren Verständnis der Einschränkungen von Computermodellen verhelfen wird. Diese Studie ist ein Schritt in Richtung einer Zukunft, in der Tierversuche nicht mehr notwendig sein werden und der einzige Arbeitsplatz für Toxikolog*innen ein Schreibtisch mit einem Rechner ist.
Originalveröffentlichung
Weitere News aus dem Ressort Wissenschaft





















Meistgelesene News








Weitere News von unseren anderen Portalen






















Zuletzt betrachtete Inhalte

Mit Masernviren gegen Krebs - Heidelberger Ärztin erhält Anita- und Friedrich-Reutner-Preis

Brokkoli-Verbindung löst Zelltod in Hefe aus - Forschungsansatz für Krebsbehandlung
Nävuszellnävus
Hackepeter und rohes Mett sind nichts für kleine Kinder! - BfR rät besonders empfindlichen Personengruppen vom Verzehr von rohen, vom Tier stammenden Lebensmitteln ab, da diese häufig mit Krankheitserregern belastet sind

Veränderungen in der Merck-Geschäftsleitung - Belén Garijo stellvertretende Vorsitzende der Geschäftsleitung und stellvertretender CEO
Bayer will Berufung gegen revidiertes Glyphosat-Urteil einlegen
Deutsche Biotech-Regionen starten Initiative: Neues Programm zur Gründungs-Finanzierung
Palmitinsäure
Kategorie:ATC-B03
Wie HIV die Immunzellen lähmt - Krankheitsmechanismus bei Infektion mit HIV entschlüsselt