El tiempo necesario para secuenciar las moléculas clave podría reducirse de años a minutos
La investigación demuestra el potencial de la secuenciación rápida y precisa de glicanos
Anuncios


Utilizando un nanoporo, los investigadores han demostrado la posibilidad de reducir de años a minutos el tiempo necesario para secuenciar un glicosaminoglicano, una clase de moléculas de azúcar de cadena larga tan importantes para nuestra biología como el ADN.
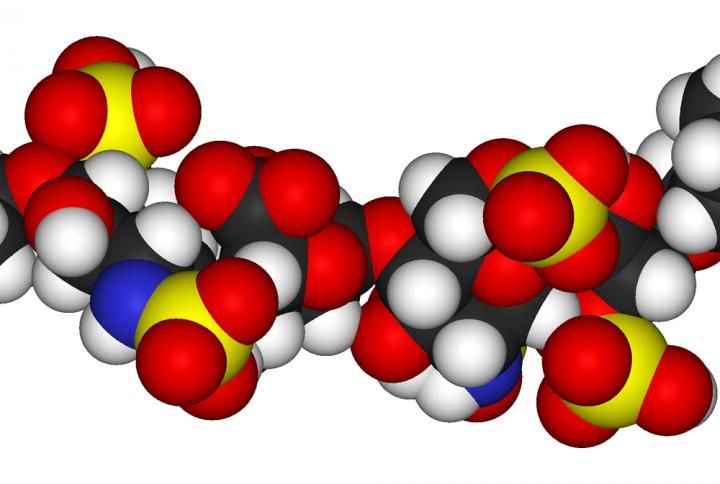
Un nanoporo y un software de reconocimiento de imágenes pueden secuenciar un glicosaminoglicano sulfatado en tiempo real.
Rensselaer Polytechnic Institute
Como se publica en Proceedings of the National Academies of Sciences, un equipo del Instituto Politécnico Rensselaer demostró que un software de aprendizaje automático y reconocimiento de imágenes podía utilizarse para identificar con rapidez y precisión las cadenas de azúcar -en concreto, cuatro heparán sulfatos sintéticos- basándose en las señales eléctricas generadas al pasar por un diminuto orificio en una oblea de cristal.
"Los glucosaminoglicanos son un complejo repertorio de secuencias, como la obra de Shakespeare o un poema de Yates es una compleja colección de letras. Hace falta un experto para escribirlos y otro para leerlos", afirma Robert Linhardt, investigador principal y profesor de química y biología química del Instituto Politécnico Rensselaer. "Hemos entrenado a una máquina para que lea rápidamente el equivalente de palabras con cuatro letras como 'ababab' o 'bcbcbc'. Son secuencias sencillas que no tienen ningún significado, pero nos demuestran que se puede enseñar a la máquina a leer. Si ampliamos y desarrollamos esta tecnología, tiene el potencial de secuenciar los glicanos o incluso las proteínas en tiempo real, eliminando años de esfuerzo".

Los dispositivos comerciales de secuenciación por nanoporos se utilizan para secuenciar el ADN, que se compone de cuatro unidades de ácido nucleico, conocidas por las letras A, C, G y T, encadenadas en una infinita variedad de configuraciones. El dispositivo se basa en una corriente iónica que pasa por un agujero de sólo unas mil millonésimas de metro de ancho en una membrana. Las hebras de ADN se colocan en un lado del orificio y se arrastran con el flujo de la corriente. Cada ácido nucleico bloquea un poco el agujero a su paso, interrumpiendo la corriente y produciendo una señal particular asociada a ese ácido nucleico. Estos dispositivos, utilizados actualmente para el trabajo de campo, son sólo una de las diversas técnicas relativamente rápidas y automatizadas para secuenciar el ADN.
Los glicosaminoglicanos, o GAG, son una clase estructuralmente compleja de glicanos -los azúcares esenciales presentes en los organismos vivos- que se encuentran en la superficie de las células y en la matriz extracelular de todos los animales y desempeñan muchas funciones en el crecimiento y la señalización de las células, la anticoagulación y la reparación de heridas, y el mantenimiento de la adhesión celular. Los glicosaminoglicanos, actualmente extraídos de animales sacrificados, se utilizan como fármacos y nutracéuticos.
Al igual que el ADN, los glicosaminoglicanos pueden subdividirse en las unidades de azúcares disacáridos que los componen. Pero mientras que el ADN está formado por sólo cuatro letras en una cadena lineal, estos glicanos tienen docenas de unidades básicas, algunas con grupos sulfato, grupos ácido y grupos amida unidos. Por ejemplo, incluso una molécula de heparán sulfato relativamente pequeña y natural de seis unidades de azúcar podría tener 32.768 secuencias posibles. Debido a este reto, la secuenciación de los glicanos sigue siendo onerosa y depende de un minucioso trabajo de laboratorio y de sofisticados análisis, en los que intervienen técnicas con nombres como la cromatografía líquida-espectrometría de masas en tándem y la espectroscopia de resonancia magnética nuclear.
Como parte de su trabajo, Linhardt, un experto en glicanos que desarrolló una variante sintética del anticoagulante común heparina, secuencia los glicosaminoglicanos para comprender las formas naturales y desarrollar variantes sintéticas.
"Utilizando métodos analíticos estándar, tardamos dos años en secuenciar el primer GAG simple", dijo Linhardt, miembro del Centro Rensselaer de Biotecnología y Estudios Interdisciplinarios. "Tenemos otro en el que hemos trabajado la mayor parte de la secuencia, y nos ha llevado más de cinco años, y probablemente nos llevará otros cinco años terminarlo".
Pensando que la secuenciación por nanoporos podría utilizarse para identificar las unidades de disacáridos de un GAG, el equipo de investigación construyó su propio dispositivo de nanoporos y sintetizó cuatro cadenas de GAG de heparán sulfato mediante el proceso quimioenzimático desarrollado por el laboratorio Linhardt. Lo más importante es que estos cuatro heparán sulfatos eran muy sencillos: hechos con combinaciones de sólo cuatro tipos diferentes de unidades de azúcar, ensamblados en una cadena de unas 40 unidades de longitud, y con una composición y secuencia cuidadosamente controladas.
El equipo hizo pasar cada heparán sulfato por el nanoporo y produjo un gráfico que representaba la tensión en función del tiempo de salida del dispositivo. Cada una de las cuatro variantes se hizo pasar por el dispositivo más de 2.000 veces, lo que aumentó la probabilidad estadística de una lectura precisa dado el diseño rudimentario del nanoporo experimental.
"El dispositivo secuenció el heparán sulfato más simple en tiempo real y produjo un patrón que nuestros ojos pudieron reconocer fácilmente de inmediato para cada una de las cuatro muestras", dijo Linhardt. "Se puede decir inmediatamente que son diferentes".
Para garantizar un análisis imparcial, el equipo introdujo los resultados en un software gratuito de aprendizaje automático y reconocimiento de imágenes que utilizaba la red neuronal profunda de Google, entrenando el software para distinguir entre los cuatro patrones diferentes e identificar cada variante de heparán sulfato. El modelo de aprendizaje automático más exitoso produjo un análisis con una precisión de casi el 97%.
"El contenido de información de una secuencia de glicosaminoglicanos puede superar con creces el de una cantidad similar de ADN o ARN, lo que significa que la capacidad de leer rápidamente las secuencias de glicosaminoglicanos abre una nueva ventana de comprensión de la compleja bioquímica de la vida", afirmó Curt Breneman, decano de la Facultad de Ciencias Rensselaer. "Este estudio de prueba de concepto vincula métodos innovadores de nanodetección con herramientas de aprendizaje automático de última generación, y muestra el poder del pensamiento interdisciplinario para ampliar las fronteras del conocimiento".
Reducir la velocidad a la que los glicosaminoglicanos pasan por el nanoporo podría aumentar la precisión, y el dispositivo puede entrenarse con unidades de azúcar adicionales y secuencias más complejas, todos ellos objetivos de investigación futuros. Linhardt dijo que la máquina tendría que aprender entre 10 y 20 unidades de azúcar para secuenciar completamente un GAG.
"Se trata de una prueba de concepto; hemos conseguido que lea palabras de dos letras", dijo Linhardt. "Una vez que le enseñemos el alfabeto completo, será capaz de leer todas las secuencias diferentes. Será capaz de leer todas las palabras".
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original
"Synthetic heparan sulfate standards and machine learning facilitate the development of solid-state nanopore analysis"; Proceedings of the National Academies of Sciences; 2021



Más noticias del departamento ciencias




































